Notícia
Mariana Pezzo
- Publicado em
17-02-2020
15:30
Pesquisadores testam algoritmos de IA no desenvolvimento de novos vidros
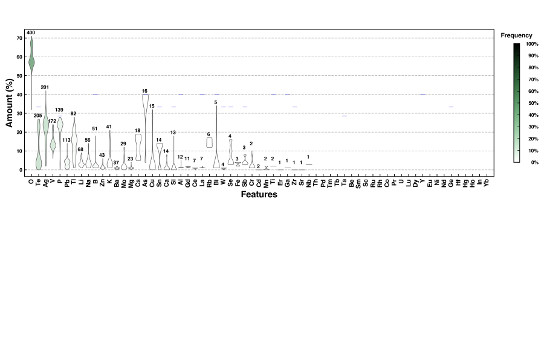
Pesquisadores da UFSCar e da Universidade de São Paulo (USP) acabam de publicar os resultados de um trabalho que dá passo importante em uma área que promete revolucionar o processo de descoberta e design de novos materiais: o uso de inteligência artificial (IA) e, mais especificamente, de algoritmos de aprendizado de máquina. O artigo - intitulado "Explainable machine learning algorithms to predict glass transition temperature" e publicado em uma das principais revistas da área de Materiais, a Acta Materialia - compara a performance de seis diferentes algoritmos na previsão de uma propriedade essencial no processo de produção e na aplicação de vidros, a temperatura de transição vítrea (Tg).
Os vidros são particularmente adequados ao uso das ferramentas de IA por várias razões. Das 10 elevado a 52 composições vítreas estimadas como possíveis, apenas cerca de 10 elevado a 5 já foram formuladas na pesquisa científica ou na produção industrial. "Utilizando o método de tentativa e erro adotado até agora, dificilmente chegaríamos em composições interessantes, por razões temporais e financeiras. O uso de algoritmos e IA abre um novo e imenso horizonte de possibilidades", explica Edgar Dutra Zanotto, docente do Departamento de Engenharia de Materiais (DEMa) da UFSCar e Diretor do Centro de Pesquisa, Tecnologia e Educação em Materiais Vítreos (CeRTEV), um dos Centros de Pesquisa, Inovação e Difusão (Cepid) apoiados pela Fundação de Amparo à Pesquisa do Estado de São Paulo (Fapesp). "Além disso, uma significativa vantagem dos vidros é que suas propriedades dependem somente da composição química. As propriedades de materiais cristalinos dependem também de sua estrutura. Por isso, para vidros, é bem mais simples modelar e controlar as variáveis a serem trabalhadas nos algoritmos", complementa.
Há pouco mais de dois anos, Zanotto iniciou trabalho pioneiro na área, junto com Daniel Roberto Cassar, pesquisador de pós-doutorado no DEMa, e André Carlos Ponce de Leon Ferreira de Carvalho, docente do Instituto de Ciências Matemáticas e de Computação (ICMC) da USP e pesquisador de um segundo Cepid, o Centro de Ciências Matemáticas Aplicadas à Indústria (CeMEAI). O grupo publicou um primeiro artigo na área em 2018 e agora, junto com quatro estudantes e pesquisadores do grupo de Carvalho, acabam de publicar o segundo artigo, na mesma Acta Materialia.
Dois grandes avanços obtidos nesta etapa da pesquisa - além da avaliação dos algoritmos, em que se destacou o algoritmo Random Forest (RF) - foram a precisão obtida na previsão de valores extremos de Tg (muito altos ou baixos) e, também, o fato de terem sido testados algoritmos transparentes, dentre eles o próprio RF.
Para a realização da pesquisa, os algoritmos foram alimentados com os dados (Tg) de mais de 40 mil composições vítreas. Zanotto explica que, das composições de vidros já concretizadas, a grande maioria apresenta Tg em temperaturas médias, o que direciona o interesse aos valores extremos, seja, por exemplo, para diminuir a necessidade energética no processo de produção (no caso das baixas Tgs), seja para obter materiais mais adequados a aplicações específicas. No entanto, como há menos dados relativos a esses vidros exóticos, também é inferior a qualidade do treinamento que o algoritmo recebe durante o seu aprendizado. Mesmo assim, o trabalho mostrou que a precisão do RF, após os ajustes realizados pelos pesquisadores, foi bastante alta, com apenas 3,5% de desvio médio do valor medido experimentalmente para vidros com Tg elevada e 7,5% para as baixas Tgs.
Dentre os seis algoritmos testados, três eram transparentes (explainable), incluindo aquele que se revelou a melhor opção entre os seis. Essa abordagem se opõe àquela em que os dados entram e resultados saem, sem que os usuários possam conhecer o processo de tomada de decisão do modelo gerado pelo algoritmo (conhecida como black box, caixa preta). O desenvolvimento de algoritmos transparentes é uma demanda crescente para a área de IA, considerando principalmente as chamadas aplicações críticas, em que um resultado equivocado pode ter consequências drásticas, como grandes perdas financeiras e, até mesmo, de vidas humanas, como é o caso dos carros autônomos, por exemplo.
"A grande inovação relatada no artigo é o uso de algoritmos transparentes, que, até onde eu tenho notícia, não havia sido reportado antes para previsão de propriedades de vidros", afirma Zanotto. "No caso da pesquisa com vidros, esses algoritmos em que conseguimos compreender o processo de tomada de decisão resultam em produção de conhecimento novo. Por exemplo, geramos uma representação gráfica dos dados que nos mostrou quais elementos químicos, em qual proporção, contribuem mais para vidros com alta ou com baixa Tg", explica o pesquisador. "Este era um conhecimento que estava nos dados, mas que, sem a ajuda da tecnologia, seria muito difícil enxergarmos", conclui.
Carvalho acrescenta que a transparência do algoritmo permite a detecção de erros e a validação do modelo utilizado. Neste mesmo sentido, o pesquisador da USP destaca a relevância da parceria com a Ciência e Engenharia de Materiais. "Ainda são poucos os que exploram o uso dos algoritmos de aprendizado de máquina para problemas desta natureza, relacionados à composição química, por exemplo. Há usos mais consagrados, como na interpretação de diagnósticos médicos. É sempre estimulante podermos mostrar uma nova área em que a Computação consegue contribuir", avalia. "Isto também envolve desafios, na compreensão de como melhor usar os algoritmos para um novo problema. Para nós, da Computação, é um verdadeiro luxo contarmos com um especialista, para que, por exemplo, identifiquem o que é de fato importante para a área e o que é descartável, uma conclusão óbvia", registra.
Agora, o grupo já está preparando um terceiro artigo, em que inserem nos três melhores algoritmos dentre os seis testados cinco outras propriedades e as relações entre elas. Um desafio que também já vem sendo enfrentado é a limpeza dos dados, ou seja, a identificação e remoção de dados de baixa qualidade, devido a falhas humanas (medida ou registro equivocados, por exemplo) ou de dispositivos (sensores). A etapa final almejada é inversão do processo de previsão, ou seja, em vez de fornecer composições e obter propriedades, informar as propriedades desejadas e receber a composição. "Queremos chegar em uma ferramenta computacional em que inserimos as propriedades desejadas, para uma aplicação específica, e a máquina nos devolve quais composições deveríamos testar", resume Zanotto.
Os vidros são particularmente adequados ao uso das ferramentas de IA por várias razões. Das 10 elevado a 52 composições vítreas estimadas como possíveis, apenas cerca de 10 elevado a 5 já foram formuladas na pesquisa científica ou na produção industrial. "Utilizando o método de tentativa e erro adotado até agora, dificilmente chegaríamos em composições interessantes, por razões temporais e financeiras. O uso de algoritmos e IA abre um novo e imenso horizonte de possibilidades", explica Edgar Dutra Zanotto, docente do Departamento de Engenharia de Materiais (DEMa) da UFSCar e Diretor do Centro de Pesquisa, Tecnologia e Educação em Materiais Vítreos (CeRTEV), um dos Centros de Pesquisa, Inovação e Difusão (Cepid) apoiados pela Fundação de Amparo à Pesquisa do Estado de São Paulo (Fapesp). "Além disso, uma significativa vantagem dos vidros é que suas propriedades dependem somente da composição química. As propriedades de materiais cristalinos dependem também de sua estrutura. Por isso, para vidros, é bem mais simples modelar e controlar as variáveis a serem trabalhadas nos algoritmos", complementa.
Há pouco mais de dois anos, Zanotto iniciou trabalho pioneiro na área, junto com Daniel Roberto Cassar, pesquisador de pós-doutorado no DEMa, e André Carlos Ponce de Leon Ferreira de Carvalho, docente do Instituto de Ciências Matemáticas e de Computação (ICMC) da USP e pesquisador de um segundo Cepid, o Centro de Ciências Matemáticas Aplicadas à Indústria (CeMEAI). O grupo publicou um primeiro artigo na área em 2018 e agora, junto com quatro estudantes e pesquisadores do grupo de Carvalho, acabam de publicar o segundo artigo, na mesma Acta Materialia.
Dois grandes avanços obtidos nesta etapa da pesquisa - além da avaliação dos algoritmos, em que se destacou o algoritmo Random Forest (RF) - foram a precisão obtida na previsão de valores extremos de Tg (muito altos ou baixos) e, também, o fato de terem sido testados algoritmos transparentes, dentre eles o próprio RF.
Para a realização da pesquisa, os algoritmos foram alimentados com os dados (Tg) de mais de 40 mil composições vítreas. Zanotto explica que, das composições de vidros já concretizadas, a grande maioria apresenta Tg em temperaturas médias, o que direciona o interesse aos valores extremos, seja, por exemplo, para diminuir a necessidade energética no processo de produção (no caso das baixas Tgs), seja para obter materiais mais adequados a aplicações específicas. No entanto, como há menos dados relativos a esses vidros exóticos, também é inferior a qualidade do treinamento que o algoritmo recebe durante o seu aprendizado. Mesmo assim, o trabalho mostrou que a precisão do RF, após os ajustes realizados pelos pesquisadores, foi bastante alta, com apenas 3,5% de desvio médio do valor medido experimentalmente para vidros com Tg elevada e 7,5% para as baixas Tgs.
Dentre os seis algoritmos testados, três eram transparentes (explainable), incluindo aquele que se revelou a melhor opção entre os seis. Essa abordagem se opõe àquela em que os dados entram e resultados saem, sem que os usuários possam conhecer o processo de tomada de decisão do modelo gerado pelo algoritmo (conhecida como black box, caixa preta). O desenvolvimento de algoritmos transparentes é uma demanda crescente para a área de IA, considerando principalmente as chamadas aplicações críticas, em que um resultado equivocado pode ter consequências drásticas, como grandes perdas financeiras e, até mesmo, de vidas humanas, como é o caso dos carros autônomos, por exemplo.
"A grande inovação relatada no artigo é o uso de algoritmos transparentes, que, até onde eu tenho notícia, não havia sido reportado antes para previsão de propriedades de vidros", afirma Zanotto. "No caso da pesquisa com vidros, esses algoritmos em que conseguimos compreender o processo de tomada de decisão resultam em produção de conhecimento novo. Por exemplo, geramos uma representação gráfica dos dados que nos mostrou quais elementos químicos, em qual proporção, contribuem mais para vidros com alta ou com baixa Tg", explica o pesquisador. "Este era um conhecimento que estava nos dados, mas que, sem a ajuda da tecnologia, seria muito difícil enxergarmos", conclui.
Carvalho acrescenta que a transparência do algoritmo permite a detecção de erros e a validação do modelo utilizado. Neste mesmo sentido, o pesquisador da USP destaca a relevância da parceria com a Ciência e Engenharia de Materiais. "Ainda são poucos os que exploram o uso dos algoritmos de aprendizado de máquina para problemas desta natureza, relacionados à composição química, por exemplo. Há usos mais consagrados, como na interpretação de diagnósticos médicos. É sempre estimulante podermos mostrar uma nova área em que a Computação consegue contribuir", avalia. "Isto também envolve desafios, na compreensão de como melhor usar os algoritmos para um novo problema. Para nós, da Computação, é um verdadeiro luxo contarmos com um especialista, para que, por exemplo, identifiquem o que é de fato importante para a área e o que é descartável, uma conclusão óbvia", registra.
Agora, o grupo já está preparando um terceiro artigo, em que inserem nos três melhores algoritmos dentre os seis testados cinco outras propriedades e as relações entre elas. Um desafio que também já vem sendo enfrentado é a limpeza dos dados, ou seja, a identificação e remoção de dados de baixa qualidade, devido a falhas humanas (medida ou registro equivocados, por exemplo) ou de dispositivos (sensores). A etapa final almejada é inversão do processo de previsão, ou seja, em vez de fornecer composições e obter propriedades, informar as propriedades desejadas e receber a composição. "Queremos chegar em uma ferramenta computacional em que inserimos as propriedades desejadas, para uma aplicação específica, e a máquina nos devolve quais composições deveríamos testar", resume Zanotto.
